StepFun presenterar Step-Audio-R1 – ljudmodellen som äntligen tjänar på längre resonemangstid
En ny generation audio-LLM visar att lång chain-of-thought inte behöver förvandla ljudmodeller till hallucinerande textmaskiner. När ljudmodeller ska
Innehåll

En ny generation audio-LLM visar att lång chain-of-thought inte behöver förvandla ljudmodeller till hallucinerande textmaskiner.
När ljudmodeller ska resonera över musik, röster eller miljöljud händer fortfarande något märkligt: de börjar fantisera. Kedjan av resonemang fylls av påhittade ord och textfragment, som om modellen läser ett manus istället för att lyssna på waveformen. Resultatet är att prestandan sjunker ju mer modellen tänker.
Forskare på StepFun menar att det inte är ljudets fel — utan språkmodellernas. I sin nya modell Step-Audio-R1 visar de att ljud-LLMs faktiskt kan bli bättre av längre resonemang, så länge man tränar dem att använda akustiska bevis istället för textliga surrogat.
I en tid där alla stora aktörer försöker knäcka koden för robust ”audio reasoning” är det här ett genombrott som placerar StepFun på kartan intill tungviktare som Google Gemini och OpenAI.
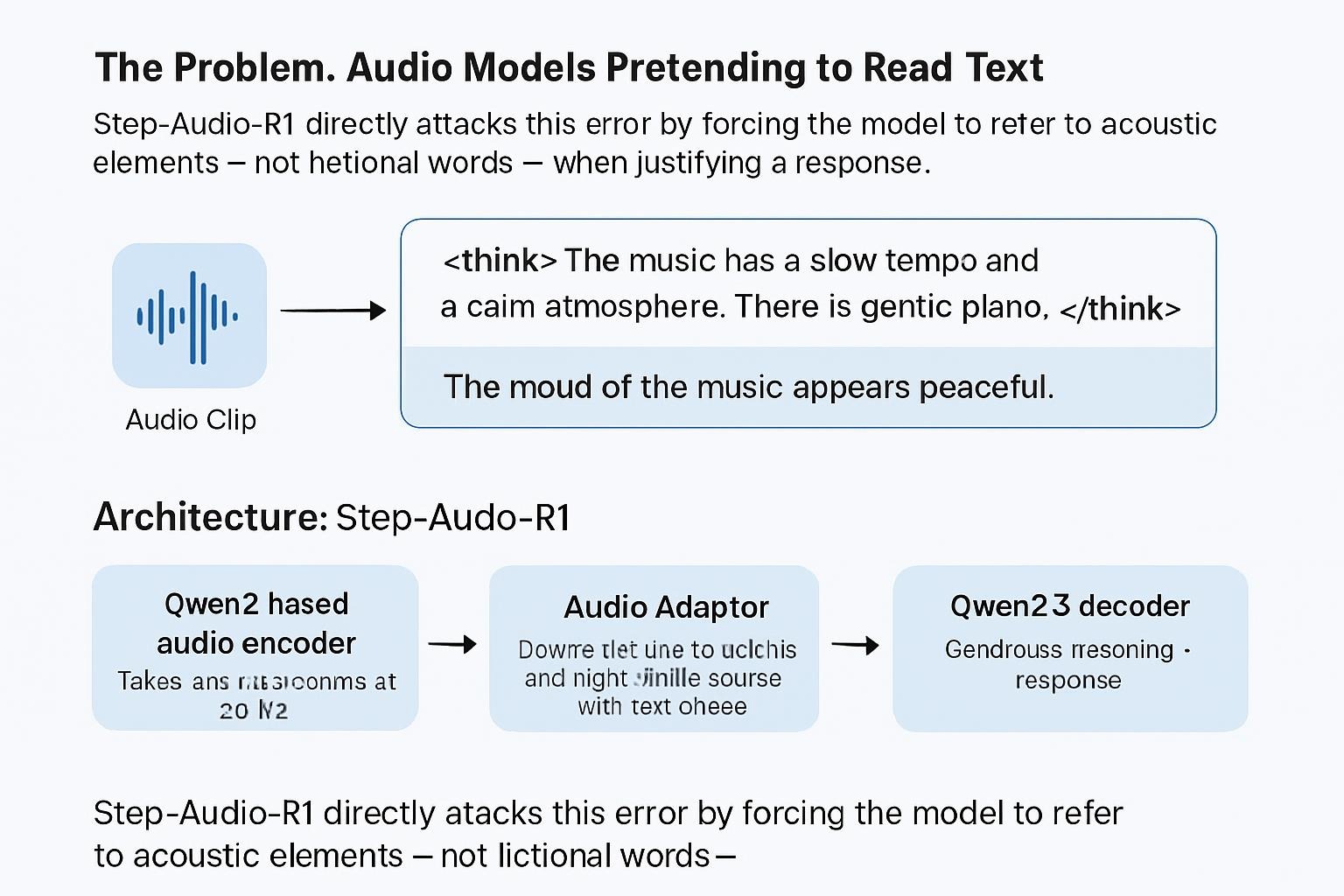
Problemet: Audio-modeller som låtsas att de läser text
Det grundläggande missförståndet i dagens audio-LLMs kallar StepFun för Textual Surrogate Reasoning.
Så här fungerar det i praktiken:
- modellen får ett ljudklipp
- modellen ska analysera känslor, bakgrundsljud, rytm, musikstruktur eller talarens tonläge
- men istället för att koppla analyserna till ljudet…
- …fyller den i resonemanget med påhittade ord, som om den försöker föreställa sig en transkription
Det gör att chain-of-thought inte förfinar svaret, utan leder resonemanget bort från ljudet.
Step-Audio-R1 angriper felet direkt genom att tvinga modellen att hänvisa till akustiska element – inte fiktiva ord – när den motiverar ett svar.
Arkitekturen: välbekant grund men betydligt smartare topplager
Strukturen i Step-Audio-R1 bygger vidare på StepFuns tidigare modeller:
- Qwen2-baserad audioencoder som tar råa vågformer vid 25 Hz
- Audio Adaptor som halverar tempot till 12,5 Hz och synkar ljudframes med texttokens
- Qwen2.5 32B-decoder som genererar resonemang + svar
En viktig nyhet är att modellen alltid producerar ett tänksegment mellan <think> och </think>. Det gör resonemanget träningsbart och kontrollerbart, istället för att gömma logiken inuti texten.
Modellen släpps dessutom helt öppet på Hugging Face under Apache 2.0 – ett ovanligt generöst beslut för en audio-LLM i toppklass.
Träningsflödet: från kallstart till audio-förankrad förstärkning
Pipeline:n består av två huvuddelar:
1. Supervised Cold Start
Ungefär 5 miljoner exempel:
- 1 miljard texttokens
- 4 miljarder audio-parade tokens
Datasetet innehåller tal, miljöljud, musik, paralingvistik, och klassiska dialog-QA-format. Alla har <think>-block, även om blocken är tomma i början.
Cold start ger modellen en grundläggande chain-of-thought-förmåga, men den är fortfarande ”språkfärgad” och använder textlogik även i ljuduppgifter.
2. Modality Grounded Reasoning Distillation (MGRD)
Det här är hjärtat i Step-Audio-R1.
För varje ljudfråga genererar modellen flera resonemangskedjor. Endast de kedjor som uppfyller tre krav sparas:
- Refererar explicit till akustik – tonhöjd, rytm, brus, timbre, etc.
- Är logiskt sammanhängande
- Ger korrekt slutresultat
Dessa kedjor skapar ett nytt, ljudförankrat CoT-dataset som modellen fintränas på.
Efter det kommer en förstärkningsfas med RLVR – Reinforcement Learning with Verified Rewards:
- Textuppgifter: belöning baserad på korrekthet.
- Ljuduppgifter: belöning baserad på korrekthet plus resonemangsstruktur (typiskt 0.8 / 0.2).
Detta gör att modellen lär sig längre men relevanta resonemang – inte korta genvägar.
Benchmark: Step-Audio-R1 närmar sig Gemini 3 Pro
På en bred svit av ljudtester (BBH-Audio, Spoken MQA, MMSU, MMAU, WildSpeech m.fl.) får Step-Audio-R1:
- ≈83.6 % i snitt
- Gemini 2.5 Pro: ≈81.5 %
- Gemini 3 Pro: ≈85.1 %
Det placerar StepFun väldigt nära världens bästa kommersiella modeller.
På BigBench Audio:
- Step-Audio-R1: 98.7 %
- Båda Gemini-versionerna hamnar lägre
Och i den realtidsanpassade varianten (streaming med ”listen-while-thinking”):
- 96.1 % reasoning accuracy
- ~0,92 sekunders latenstid
- slår GPT-baserade realtidsmodeller
Ablation-studien: Vad gör en audio-LLM bra på att resonera?
Forskarna lyfter tre viktiga insikter:
1. Belöning för resonemangsform behövs
Annars kapar RL-träning bort chain-of-thought helt, vilket sänker prestanda.
2. ”Lagom svåra” uppgifter är bäst för RL
För svårt = kaos.
För lätt = ingen förbättring.
Ett ”mellanband” i pass-at-8 ger stabil träning.
3. Mer ljuddata hjälper inte om den är slumpvald
Kvaliteten på etiketter och frågor är viktigare än storleken.
Dessutom introduceras en self-cognition-correction där modellen tränas att sluta säga ”Jag kan inte höra ljud” – en vanlig hallucination i ljud-LLMs.
Analys: ett verkligt steg framåt för ljudbaserad AI
Det som gör Step-Audio-R1 angelägen är inte att den slår nya rekord i ASR, utan att den:
1. Löser audio-LLM:s största strukturella svaghet
Nämligen att resonemang förvandlas till textliga gissningar.
2. Visar att chain-of-thought faktiskt fungerar i ljudmodeller
Det kräver förankring – inte fler parametrar.
3. Ger en reproducerbar träningsrecept
MGRD + RLVR är en konkret pipeline andra aktörer kan återskapa.
4. Närmar sig de bästa proprietära modellerna
Men är öppen källkod, vilket accelererar hela fältet.
Step-Audio-R1 visar att ljudmodeller inte behöver vara begränsade till transkription.
De kan resonera — och göra det bättre än många trott.
Key Takeaways
- Step-Audio-R1 är en av de första ljud-LLMs som tjänar på längre chain-of-thought.
- Modality Grounded Reasoning Distillation lär modellen att använda faktiska akustiska bevis.
- Arkitekturen kombinerar Qwen2-encoder + Qwen2.5-decoder med strukturerad
<think>-logik. - Modellen matchar eller slår Gemini 2.5 Pro och närmar sig Gemini 3 Pro.
- Träningsreceptet (SFT + MGRD + RLVR) är reproducerbart och öppet.